0x00 为什么采集天气数据
一日走在路上,在想关于销售预测的相关,发现很多预测状况都与天气有巨大的关联,最近也正好在看爬虫相关的,搜索了一番,发现网上有按月展示的数据,但无数据包,所以开始了自己爬取数据的过程。由于网站提供的数据很好采集,也无限制,所以采集的很顺利,总共采集了大概800W条数据。
0x01分析页面
在城市列表页:http://lishi.tianqi.com/ 可通过每个城市名点击,进入单个城市的详情页:http://lishi.tianqi.com/beijing/index.html (以北京为例),在此页中存有北京市天气的详细数据列表:
点击后进入月天气详情页:http://lishi.tianqi.com/beijing/201806.html (北京市2018年6月天气详情页)
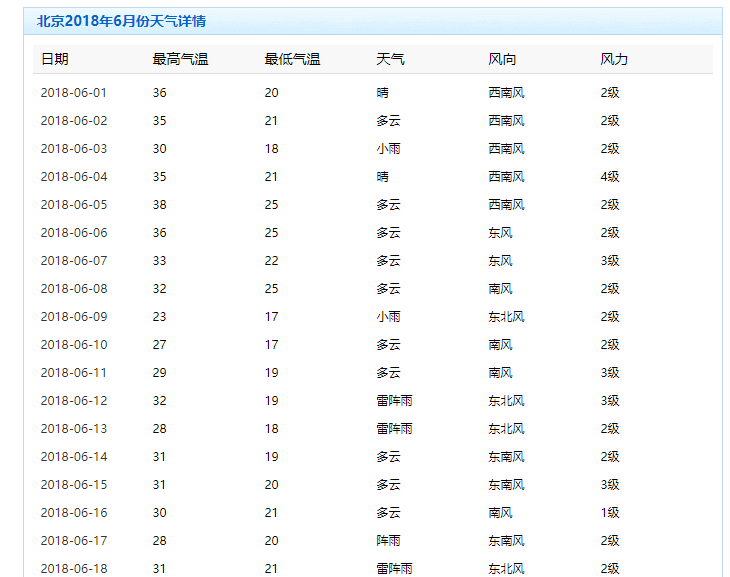
由此获取的目标数据就在城市的月份天气详情页中。
0x02 采集过程
- 从城市列表页获取每个城市URL;
- 利用每个城市URL通过组装生成城市月份URL;
- 爬取每个城市月份页中的天气数据;
- 每个城市一个文件存数据;
0x03 代码实现
1 . 获取城市列表
访问https://lishi.tianqi.com/,获得城市列表写入citylist.csv。
1 | def getCitylist(self): |
2.城市月份天气页处理
访问城市月份天气页,通过BeautifulSoup提取数据
1 | def cityDl(self,urllist,cityname): |
3. 控制函数
由于月份格式需两位,所以10月之前的月份需要补0,例如2018年6月需为:201806,所以单独写了一个函数生成月份列表。当然也尝试了python的库,发现实现很麻烦,所以自己实现了月份列表的方法
1 | def monthList(self, beginDate, endDate): |
控制函数首先读取 getCitylist生成的citylist.csv,然后通过monthlist获得需要抓取的月份list,通过循环控制生成城市的天气urllist,然后调用cityDl抓取天气数据
1 | def taskControler(self): |
0x03 关键点
整体来说这个网站的抓取很简单,笔者甚至认为算不上爬虫任务。在其中有两个关键点帮助笔者高效的完成了任务:
1. python的数组切片
python对数组的切片功能很强大,以数组:[0,1,2,3,4,5,6,7,8,9]举例
取第四至第六个元素:
由于切片中用的range,所以需要4:7
IN:
1
2a=[0,1,2,3,4,5,6,7,8,9]
a[4:7]OUT:
1
[4, 5, 6]
取倒数第一个元素
IN:
1
2a=[0,1,2,3,4,5,6,7,8,9]
a[-1]OUT:
1
[9]
取后5个元素
IN:
1
2a=[0,1,2,3,4,5,6,7,8,9]
a[-5:]OUT:
1
[5, 6, 7, 8, 9]
取除去后5个元素的数组
IN:
1
2a=[0,1,2,3,4,5,6,7,8,9]
a[:-5]OUT:
1
[0, 1, 2, 3, 4]
每三个数取一个数
IN:
1
2a=[0,1,2,3,4,5,6,7,8,9]
a[::3]OUT:
1
[0, 3, 6, 9]
python提供的切片真的很方便,当然还有很多骚手法等待大家挖掘,这里就不一一列举
2. Beautiful Soup
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
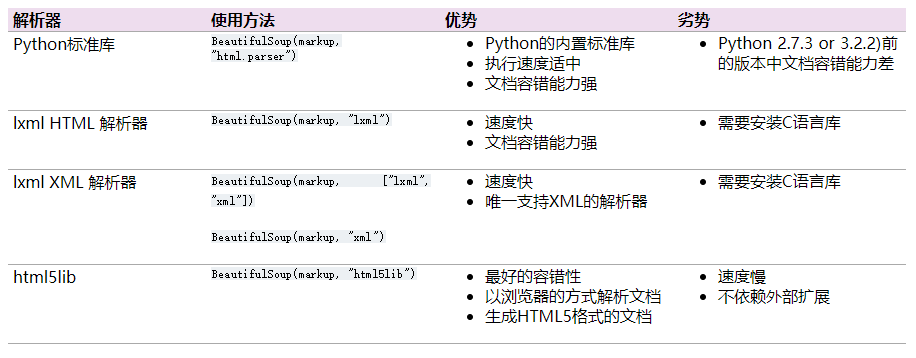
Beautiful Soup提供了一套十分好用的html解析器,可以不用直面正则表达式,并且可以使用很容易理解的代码完成页面解析、数据提取。以下是各种解析器的对比,具体使用可以参考官网。
在本例中,笔者使用了beautiful soup去城市月份天气页中过滤天气数据:
1 | ul_list = weather.select('ul') |
0x04 效果
代码总共运行了有3天左右,中间由于错误和断网终端了几次,实际耗时更多。共采集了3180个城市的数据,300M大小。
0x05 可改进点
1.错误及异常处理
在运行过程中,多次因为网络原因和URL错误导致程序中断,可以通过添加异常处理进行跳过,并记录访问异常URL
2.多线程
单线程跑程序过慢,大部分时间消耗在等待HTTP响应上,其实可以通过多线程,并行任务。
不过python的多线程只会调用一个核。
Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
后期有时间优化。