0x00 题记
敏捷其实上学就听过,scrum、XP等等,但上学没有经历复杂的软件项目实施,对软件工程的很多概念和规范是浮于表面,知其然,不知其所以然。然后最近有几个事一直和“敏捷”相关:
去年在阿里数据中台培训时,讨论到数据中台的开发模式,阿里教练说,数中是无法用“敏捷”方式的,但至于他们用了什么样的模式并没有说;
我们在对一个客户在做BI实施时,由于他们的业务交付团队一直用敏捷的方式交付的,所以也需要我们用敏捷交付,当时由于第一点的原因,我是反对且内心是抗拒的;
公司在讨论数中我们到底用什么模式开发时,在说到底是“瀑布”还是“敏捷”,突然觉得这件事是需要想想的;
再看中台相关时,由于会很多地方带上“敏捷”的讨论,我突然想如果第一点是错误的呢?
所以我需要对敏捷做一定了解,再做判断,恰巧看到了Thoughtworks出版的这本书《深入核心的敏捷》,帮助我了解敏捷开发,这本书也确实没有让我失望,为了开了一扇门。
0x01 核心原则
1.起源
2000年前,软件交付项目的失败或交付困难的比例很高,很多牛逼的软件开发者不满意瀑布软件开发的方法做交付,在各自工作实践中用了很多方法,涌现了很多新的软件开发方法。2001年17位软件大师在犹他州的小镇雪鸟,总结了当时涌现的开发方法所具备的特点发布了“敏捷宣言”。让我们再回顾他们:

敏捷软件开发宣言
我们一直在实践中探寻更好的软件开发方法,身体力行的同时也帮助他人。由此我们建立了如下价值观:
个体和互动 高于 流程和工具
工作的软件 高于 详尽的文档
客户合作 高于 合同谈判
响应变化 高于 遵循计划也就是说,尽管右项有其价值,我们更重视左项的价值。
2.敏捷宣言到底有几句?
六句!但大家大都记住了中间四句,我们一直在实践中探寻更好的软件开发方法,身体力行的同时也帮助他人。由此我们建立了如下价值观这句话告诉我们敏捷宣言是不断实践中总结出的价值观,价值观不是具体实践的目标和实践,而是价值取向。所以有的团队说,我们敏捷了,因为我们做了迭代开发,这种单纯的实践=敏捷是不成立的,我们需要多维度了解团队的价值观知否符合敏捷的价值观。
尽管右项有其价值,我们更重视左项的价值。这句话是敏捷宣言中最重要的一句,在敏捷过程中,会有这种现象:“敏捷说了不需要文档,所以我们以后不用写文档了”,“敏捷说了不需要计划,那我为什么要给计划”,这些都是敏捷转型方向上的错误。宣言中价值观用了“OVER”(高于),A高于B,并不是用A舍弃B。当初17位大牛,早就遇见到这样的问题,所以用了最后一句话强调,并不是让我们要舍弃右项实施左项。
3. 开发人员的客户思维
作为开发人员,很多人有“技术至上”的自负心理,这都是与他们理工科的成长背景有关系。“因为,所以,得证”,这是数学里常见的论证不走。但事实却不会这么简单。一个需求,必定有商业和业务上的考量,在实现过程中,还需要考虑不同的解决方案,各个方案中存在的风险和投入成本。对业务理解的一致,所有努力朝一个方向,才能获得成功。
在现实中,客户由于对技术和实现方式的不了解,经常challenge我们,会不专业,也不油耗。我们会时常会在内心质疑客户,但他们不是第一个,也不会是最后一个,但我们要思考的是客户为什么会这样,他们是为了解决问题的,并不希望项目的失败。数字化的技术、交付组织只会越来越复杂,如何教育我们的客户更是一个大话题。
引用书中的一个故事,让我们谨记客户思维的重要性。当我们为了谋生而一头扎进代码的世界里时,其实与小时候老家镇上铁匠铺的铁匠并没有区别。那样的我们,不用顾虑顾客为何需要打造那么一件奇形怪状的铁器;在顾客一而再地提出挑剔意见时,我们一开始争辩,后来丧气,最后麻木了。那样的我们,数十年如一日,作为铁匠的技艺愈加成熟。直到有一天,一种叫“铸造机床”的远在天边的东西,夺去了我们的饭碗。
0x02 核心实践
1.专业团队、自组织、带头人
作者在书中从一次汽车贴膜看专业团队的专业服务。所有工作高度被高度并行化。四个人同时施工,一个人在缝真皮方向盘套,一个负责贴车左侧窗户的膜,一个负责贴右侧的膜,一个负责贴前后挡风的膜。其次,大家没有清晰的角色划分,缝方向盘的人在完成手头工作后,会立刻加入贴膜的工作,贴膜完成后,两名工人开始帮车打蜡和内饰清洁,整个过程自然而连贯,完全自组织,不需要人安排和监督。所有人都掌握了整套技能,并没有严格的分工,整个过程已经被高度优化过,环环相扣,环环相融,无论时间还是材料的浪费都被降到最低。
在做“新车去异味”项目时,一头扎进充满延误车厢的人是这家店的老板,是的,他还是上面四人之一。在作者看来是一个称职的带头人。凡事冲在前面,以身作则,勇于承担一些困难甚至危险的工作。而作为客户的作者,自然也对这个团队平添了一份信任和钦佩。
2.团队的精进之道
当我们带领一个团队时,我们想的总是,如何做好任务分配,平衡战斗力和交付最好结果。于是,我们下意识简单的因才分工,随着项目的进展和人员流动和意外的发生,项目后期会处处制肘,以加班以示诚意。作者在工作中遇到一个高人,他在项目开始的时候,问清楚每个人擅长的部分,然后让每个人去做自己不擅长的部分,不会?去找擅长的人帮忙,虽然看起来有点乱,但他负责的项目从来没有出问题。这是“把项目成功交付看作能力建设副产品”口号的一种朴素实现。
很多团队能力不强,团队的领导就总是在向外寻求方法和帮助。这个行为本身没错,但是做这件事的人无法摆正心态,很多人潜意识是假设团队成员能力不变的,期待在此前提下通过一种魔法般的方法改变团队绩效,这种思路在真实世界中是走不远的。在Thoughtworks、认为,软件开发中的一切问题,根本上都是人的能力问题。如何发展每个成员才是关键问题,我们采取的一切实践,核心目标只有一个:发展人的能力,所以才有耸动的口号:“把项目成功交付看作能力建设副产品”。
一个人要划任务、估时间、在做的时候计时、根据实际结果进行反思。我们可以把这个方法做成非常邪恶的、仿佛流水线上工人的强制要求。我们不关心员工为什么超时,就通过这种方法控制程序员,要求每个人按照一个死板而讲话的步骤做一些简单重复的机械动作。也可以用这个方法来锻炼一个人自我 认知和发现知识漏洞等能力,促使他快速成长,等他成长起来马上给他更重要的任务。这两种结果的差异,背后是领导者认知的差异、团队成员认知的差异。作为敏捷宣言里的一句话表达出来:“个体与交互 高于 流程和工具”。团队流程和工具,是为了成就个体,促进交互?还是为了抹杀个体,消除交互?这微小而关键的差异,是一切的本质。
3.需求风险的坏味道和对策
<1>识别坏味道
软件工程是一件专业性很强的事情,我们必须教育客户,让他们明白管理软件项目,有很多场景我们也经常遇到:
“这个需求我们实现过,只需要一周时间就可以完成。”
客户正在插手工作量的估计,这是最危险的,我们应该让客户完全了解我们的工作量估计系统是如何工作了,要强调我们的工作量合理、公平、有效
“关于这个需求,你做个方案给我选一选。”“这两个方案我都不喜欢,要不你们再想想”
这代表客户不理解在软件开发中,“需求分析”也是工作量的一部分,AB稿在设计界广泛存在,并且作者认为是低效的决策方案。
“这是领导要的,我也没办法。”
客户正在抛开自己的决策责任,尝试用最不负责任的方式逼迫你答应需求。
<2>对策
尽可能靠近决策者
做系统决策人
不要给选择
管理结果而非解决方案
建立游戏规则
4.结对编程
极限编程中的极限是指将我们认同的有效软件开发原理和实践应用到极限,如果集成测试很重要,那一天多次集成,反复的进行回归测试,所以我们要做持续集成,如果代码评审很重要,所以我们要一直进行代码评审,所以我们要做结对编程。
设计和编程都是人的活动,忘记这一点,将会失去一切
结对编程的好处:
- 培养新人,促进沟通,提升团队整体能力;
- 更好的知识共享和信息交流,促进团队协作;
- 促进团队成员的沟通,提升凝聚力。
5.站会
说到站会,就会有三个经典问题:
- 昨天完成什么
- 今天准备做什么
- 遇到什么障碍
当团队养成随时沟通的习惯后,站会还有存在的必要。站会总是有人迟到,吃早饭,玩手机,我们还需要站会吗?从团队发展阶段模型,团队发展一般需要依次经历几个阶段:
- 组建期
- 激荡期
- 规范期
- 执行期
- 休整期
站会在每个阶段承担着不同的作用:
组建期和激荡期:建立信任
规范期和执行期:关注价值流动
执行期:仪式感
敏捷不是遵循“最佳”实践,而是要搞清楚实践在什么环境下解决什么问题,然后再合理地对实践进行裁剪和改进,这才能保持敏捷力。
6展示会的七宗罪
- 准备工作没做好;充分做好准备工作
- 没有上下文铺垫;开始演示前先介绍上下文
- 逐条过AC;以功能为单位演示
- 企图覆盖所有路径;只演示关键路径
- 过多提及跟演示无关内容;只提及要演示的功能
- 认为展示仅仅是BA或QA的事情;人人都可以展示
- 不熟悉的新人负责展示;展示前先充分了解系统和业务
0x03 管理体系
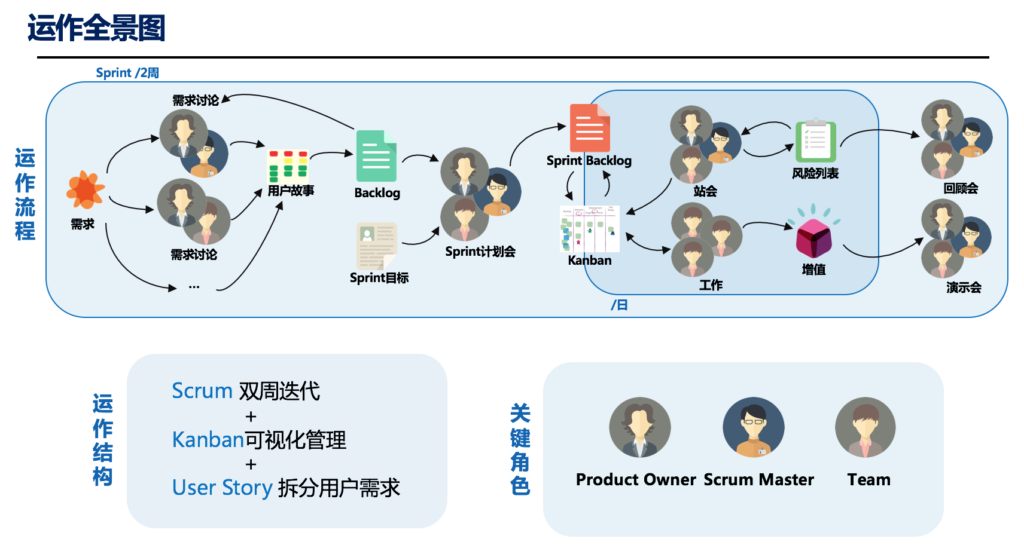
1.Scrum
<1> 三个角色
角色一:PO的任职资格
在作者见过的Scrum团队中,绝大部分PO是不具备做PO的资格,不是说能力,而是资格。PO从职责上讲拥有,Product Backlog,负责决定哪些功能进,哪些功能不进以及优先级是什么,是必须有资格能够负责产品的方向。换句话说,PO通常是资方而不是劳方的人,PO要么给项目提供资金,要么是他的代言人。
角色二:Scrum Master的悖论
Scrum Master的使命就是把自己做没,这个角色深刻反映了Scrum内在不一致。如果Scrum Master做得好,他会把自己的大部分工作做没,变得越来越轻松。按照Scrum Master定义,从根本上上是一个教练的角色,教会自组织、教育po、教育开发团队,教育其他干系人,评价教练的唯一标准就是被教的人不需要他
角色三:开发团队自组织的假象
<2>四个会议
Sprint 评审会
如何评价评审会的效果?唯一的标准是,会后有没有对Backlog做出调整
Sprint计划会
实际上应该分开两个会IPM、IKM,讨论做什么和如何做
每日站会
最流于形式的会,成为类似考核会一样,考量工作是否饱满,大家证明自己没闲着。应该关注什么?进度、障碍、新知及是否要进行调整,关注的是接力棒而不是运动员
Sprint回顾会
2.敏捷实践
剑道中有这样一个心决:守,破,离。
- 守:最初阶段须遵从老师教诲,认真练习基础,达到熟练的境界。
- 破:基础熟练后,试着突破原有规范让自己得到更高层次的进化。
- 离:在更高层次得到新的认识并总结,自创新招数,另辟新境界。
0x04 转型
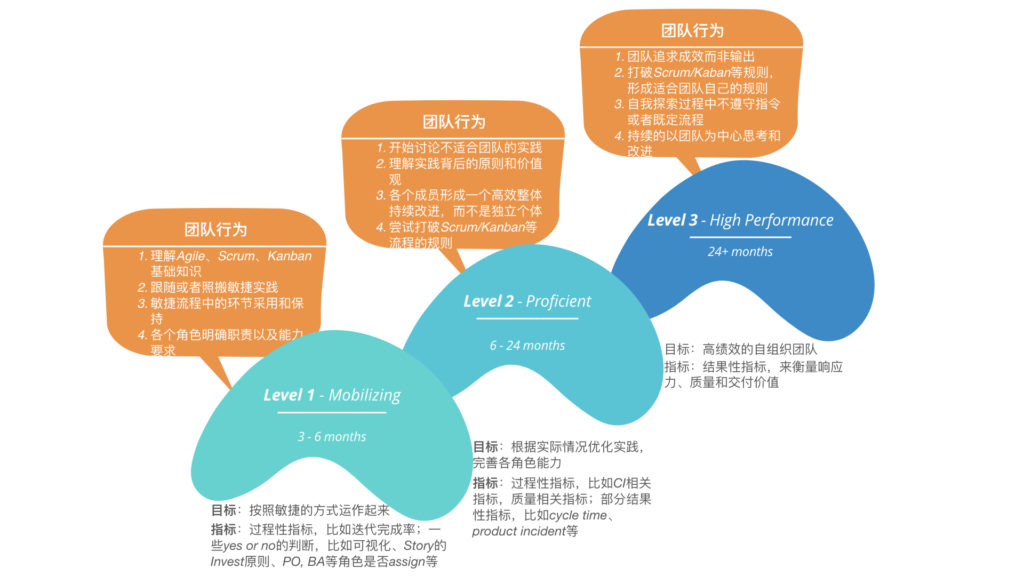
1.敏捷转型的三个阶段
阶段一:建立敏捷流程,缩短交付周期;这个阶段主要目标是将需求反馈、开发质量反馈、以及改进周期缩短在一个迭代内。
阶段二:引入技术实践,质量内建,减少返工;这个阶段主要目标是提升开发人员意识,从而提升开发阶段产出的质量水平,减少后续环节的返工。
阶段三:提升价值交付效率和响应力;这个阶段目标就是培养成员的自我提升意识,软对的自我改善能力,并帮助团队建立自我改进习惯
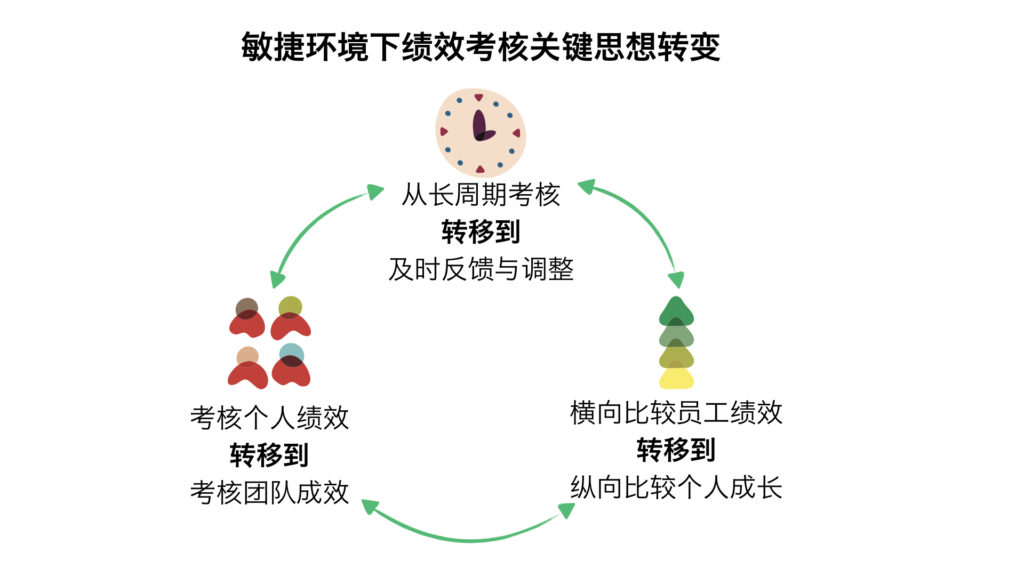
2.绩效考核,敏捷转型鸿沟
绩效考核,绩效排名以及年度考核是管理上七大顽疾之一。
传统绩效考核与敏捷价值观间,在对象、目标、考核周期、考核结果、负责人都有巨大冲突。绩效考核的目标,本质上就是如下问题:
- 如何决定给员工涨多少薪水?
- 怎么决定谁应该升职?
- 怎么决定谁应该被解雇?
- 员工如何能知道他们需要做得更好并努力提升自己?
真正高绩效的员工,未必为了金钱而工作,最能激励他们的是有挑战的工作和合理的自主权。通过对于产品价值、质量交付及交付效率的度量,透明公开可视化这些指标,更容易激励员工做得更好。
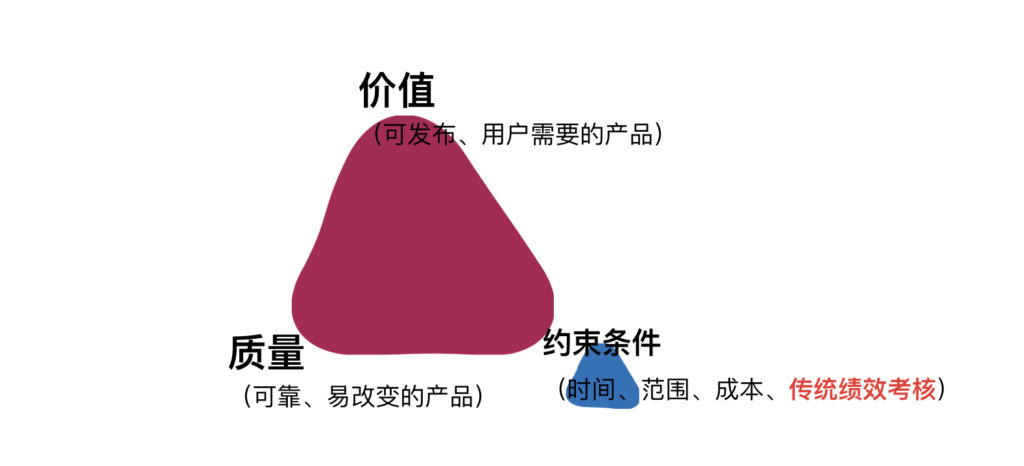
正如《管理3.0:培养和提升敏捷领导力》所说,所有变革最后的失败都是管理的问题对于转型中的组织,特别是一线管理人员,应该把绩效考核这种管理手段当成“敏捷铁三角”中的一角来对待,那就是调整约束。把它当成跟时间、成本、资源等类似的约束因子来统一管理。一家企业之所以存在,有其独有的文化和运作规则,只有调和好约束,才能最大化敏捷的价值,如下图所示
0x05 案例
1.技术决策
作者在书中的案例,由于一个自制存储框架的“鲁莽”技术决策,本身一个很重要的决定,却没有拿到台面上和客户讨论。通过很尴尬的和用户解释为什么从一个自制存储框架到成熟的存储框架。客户虽然不高兴,但认为佐证正在改善这些,开始设立技术治理小组,进行讨论,积极的应对技术债。
技术领导者的倾向从追逐“正确”的决策,变成开始作出“合适”的技术决策。
我们应当让客户参与到技术决策中,团队做出决策,承受自己决策的后果,但是和客户更多的分享上下文,客户保留否决的权利。如果客户不认可,分享原因后,团队可以更好的提出别的方案
2.工程师文化
<1>工程师文化与kpi文化
- 工程师文化是由内而外的引导和自然发生,KPI文化是由外而内的信仰和强行注入;
- 工程师文化着眼未来, KPI文化活在当下。
- 工程师文化痛恨KPI,我不爱的我不做,我爱的我疯狂。 KPI文化唯KPI说话,爱不爱都要像战士一样完成。
<2>工程师文化的前提条件
信任:leader和产品对工程师绝对的信任是工程师文化的最基本条件。如果他说要用一个更优雅的方法解决一个问题,但要花更多的时间,请你选择相信他。好的工程师非常懒惰,他这么做一定是为未来的工作提高效率。
卓越的技术领袖存在:领导如果对技术没有信仰,只把技术当成工具,就很难说这个团队会有工程师文化。说白了不是每个不懂技术的领导都懂得欣赏优雅代码产生的美和对未来产生的深远影响。
技术列为KPI:参加晋升面试的时候,50%以上的技术人员讲的都是产品(what),而不是技术(how),并且他们都晋升了…..这源于业务BU总是把业务当成KPI的唯一衡量手段:技术好不好有什么关系?今年不出事,明年我已晋升。如果没有技术KPI,技术就会总被放在次优先级。
0x06 读后感
其实看完正本数,依然要重读第一章,应该深刻记忆敏捷宣言,记住他是一种价值观,而不是一种实践,在每个项目中我们都应因地制宜的制定自己的敏捷策略,最佳实践永远都是一种参考。
了解完敏捷后,突然发现敏捷和中台的很多目标都是互通的,都是在加强自己的“用户响应力”、技术即业务、中台的理念更像是把敏捷的思想从一个交付团队上升到了企业级,这其中不仅仅只有工程师组织,还有更多业务和商业上的考量。
对敏捷的了解还是浮于表层,希望以后可以在实践中践行敏捷价值观。